
Developing Deliberation Augmented AI-Infused Civic Participation Platform using BERT
Roles
Research lead at KAIST
Selected as researchers for Exploratory Research Program, KAIST
Goals
Collecting data to detect deliberative / non-deliberative petitions.
Developing Deliberation Augmented AI-Infused Civic Participation Platform using BERT
Details
Crawling a national petition posts to create a BERT-based Korean classifier model ( 70,216 posts )
Recruited the participants to label deliberative / non-deliberative petitions
Developed an AI based Filtering System and Design Interfaces for Online Petition Platform
This work is more about how I developed a NLP Model by using BERT. If you are interested in how I applied this model to develop an interactive system and design Interventions (CHI LBW) - click here!

“We developed A BERT-based Korean classifier model that can classify the political sentiment of national petitions in a low-resource environment”
1. Deliberative BERT Modeling Pipeline

Crawling a national petition posts to create a BERT-based Korean classifier model that can classify the political sensibilities of national petitions in a low-resource environment
We collected 70,216 posts.
Labeling data for non-deliberative post classification criteria
2. Data Labeling & Criteria

We used LabelBox to Label the Petition Posts

Labeling Criteria for Modeling

3. Building Deliberative BERT Model
BERT is a new language representation model, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. (Devlin et al., 2018)

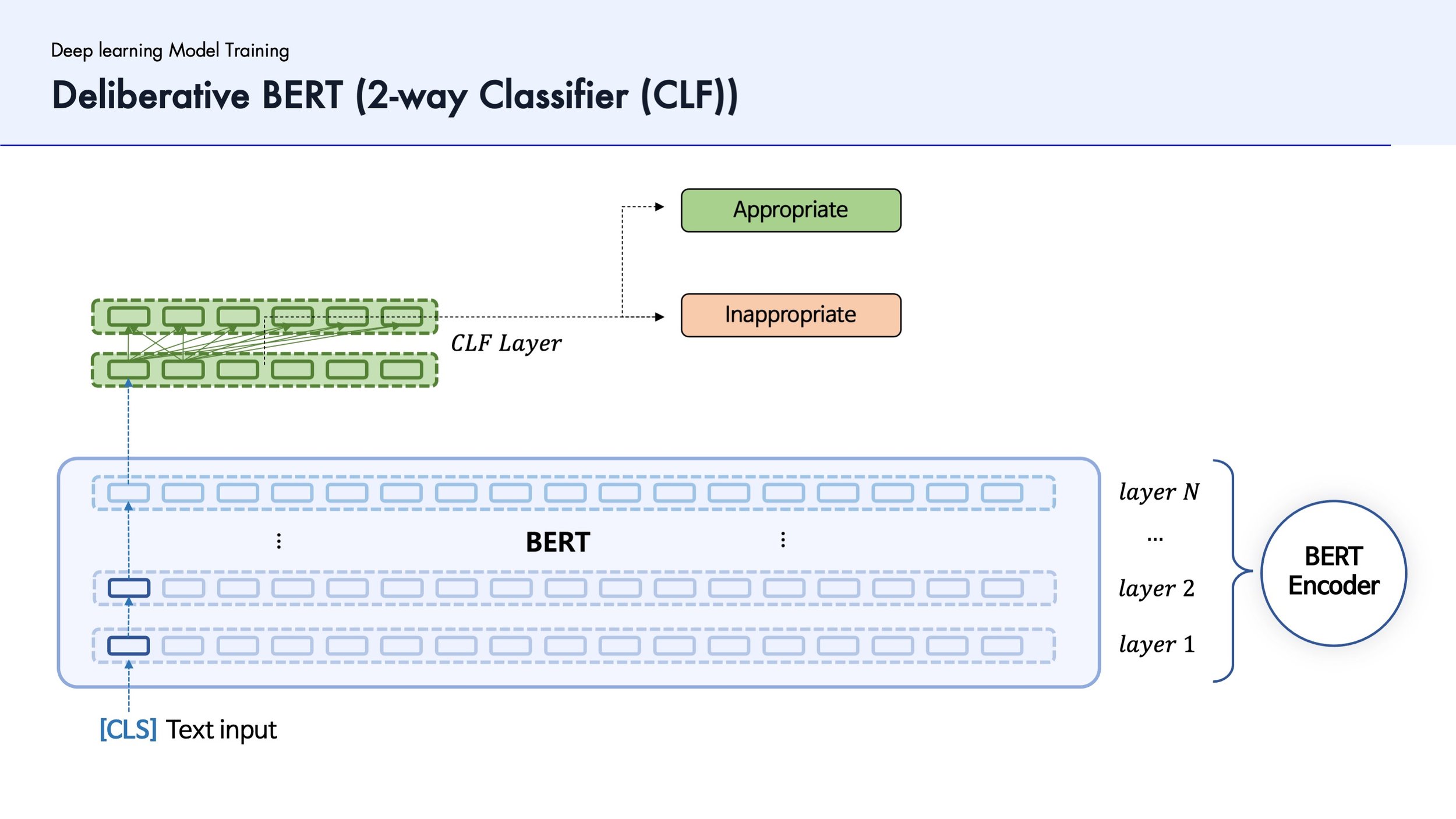
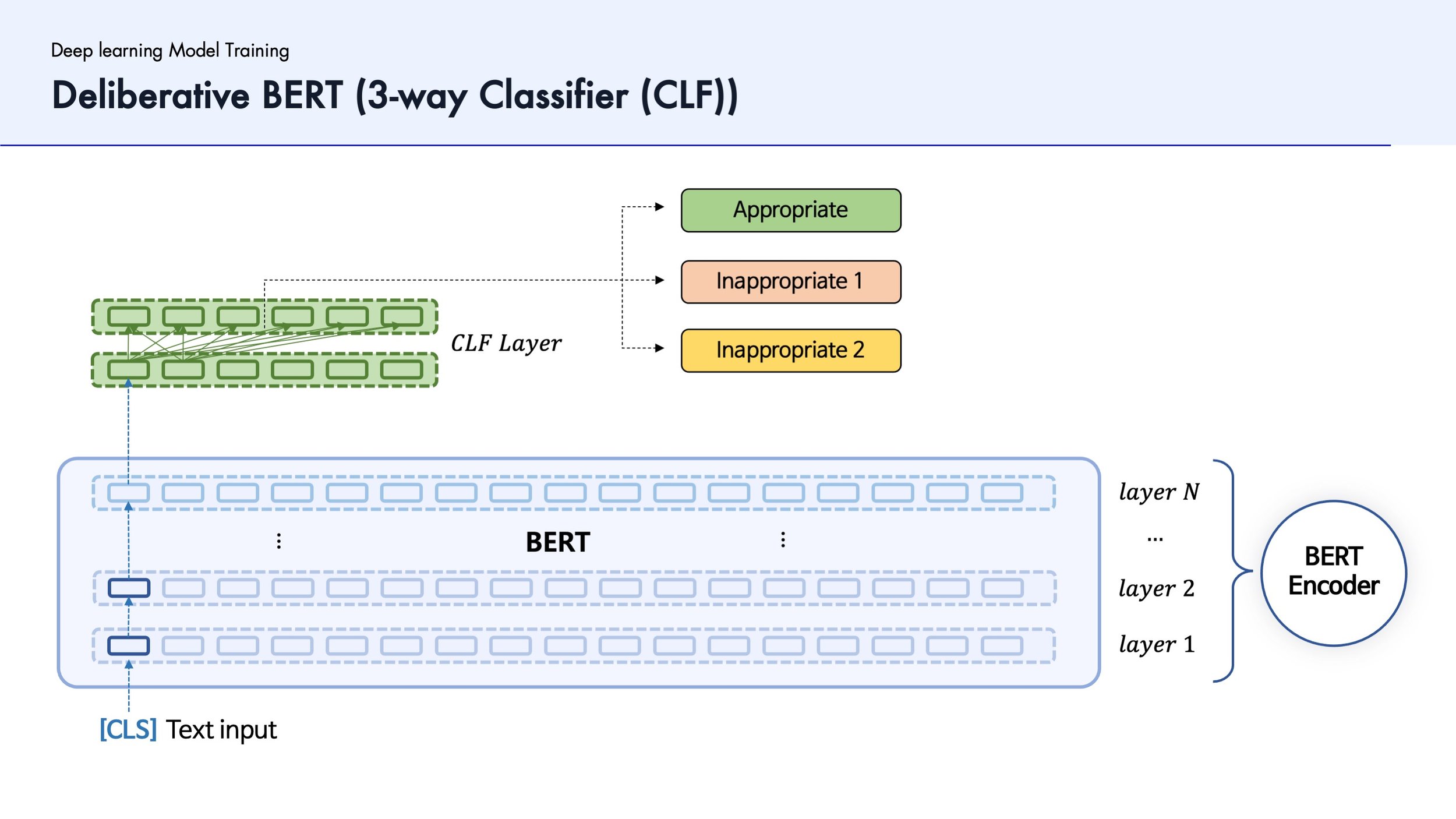

4. Comparing among Models Regarding Accuracy
Then, we compared the accuracy of three models to choose the model which records the highest prediction rate. The model is the ‘two way classifier’.

5. Choosing the Best Model & Maximizing Prediction Rate
Finally, we chose the ‘two-way classifier model’ and developed to maximize the accuracy of model.
By controlling the length of text information, we compared it affected the accuracy level.
Even though being in the low-source environment, we developed the first models which predicted the non-deliberative models with an accuracy of about 80.


6. BERT’s non-deliberative classification,
which is difficult to judge by LDA
Example of a value that was input from a learned model and immediately output
